
A $100k Prize for a Decentralized Inflation Dashboard
Build a censorship-resistant inflation dashboard. If we pick your project, we'll fund it with $100k.

Note: This post was originally created at 1729.com which has evolved into thenetworkstate.com.

Inflation is a monetary phenomenon, a function of money printing. But it is also in part a social phenomenon, a function of mass psychology. If enough of the right people believe that inflation is going to happen, it will. As such, when inflation is happening, there is often a push to censor discussion of inflation itself, under the grounds that discussing the problem actually causes it in the first place. That is exactly what happened in Argentina and Venezuela over the last decade.
And that is why the world needs a global, decentralized, censorship-resistant inflation dashboard. For the next 90 days, we're accepting submissions for this project. We'll invest $100k in the best entrant if you end up starting a company, with possible follow-on investment from @Sergeynazarov, @APompliano, @RussellOkung, and @RajGokal. Additionally, if the best dashboard uses Chainlink's crypto oracle technology to get the relevant data on-chain, they'll be eligible to receive an additional $100k grant in LINK tokens. Read the terms and conditions and submit your entry here.
In this post, we discuss why such a dashboard should exist, how one might go about building it, and how we might fund it should you come up with a good effort.
Why an Inflation Dashboard Should Exist
Why do we need an inflation dashboard? Because trillions of dollars have been printed over the last year – and it's not just dollars. Many countries besides the US have been printing fiat like mad to fund the response to COVID. Figures that shocked and stunned ten years ago ($787B for the bailout!) no longer warrant a headline today, though they may well result in headlines tomorrow.
If inflation is a government-caused problem, we can't necessarily rely on government statistics like the CPI to diagnose it or remediate it. Indeed, in places with high inflation, censorship and denial is the rule rather than the exception.

Think of it as coinmarketcap.com, but for inflation: the next dashboard that crypto people around the world will refresh every day.

How You Might Build An Inflation Dashboard, in Brief
Here's the high-level version of what we want to see in an inflation dashboard.
Obtain price data. This is actually one of the hard parts! See below for more detail, but in short it's not that easy to get good data. As such, your data acquisition and verification pipeline will be an important part of your submission, should you choose to enter the competition.
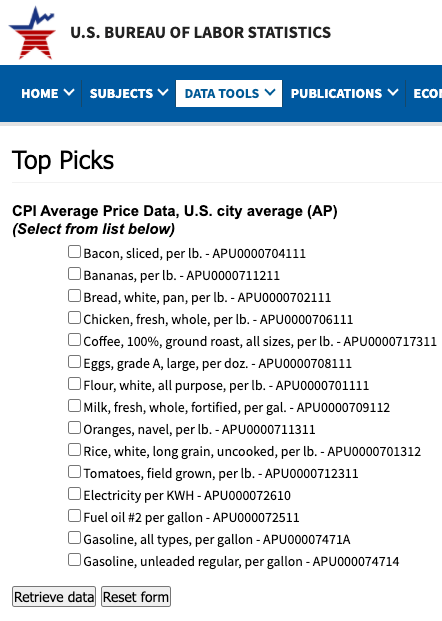
Identify a large basket of goods. Let's assume for the sake of argument that you can get verified price data. A good data source should allow you to isolate a large (but finite) basket of goods with reliable data from different sources. Just like Coinmarketcap.com tracks the prices of 10000+ digital assets over time across many exchanges in different countries, you want to track the prices of N basket items over time across many merchants in different countries. For comparison, here are some of the goods that the US Consumer Price Index (CPI) tracks.
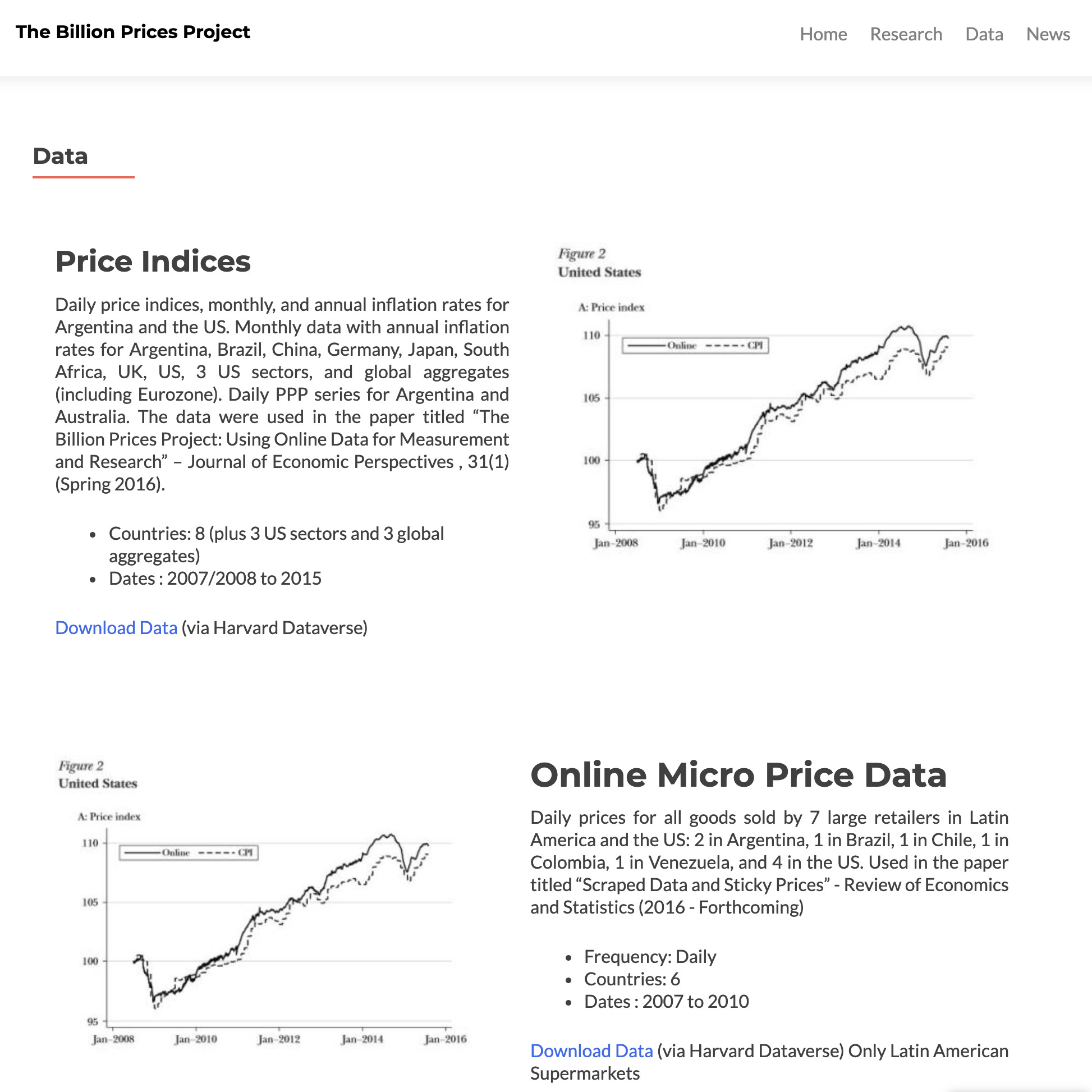
Put price data on-chain. Once you have good price data, you want multiple censorship-resistant, decentralized, moderately-available data stores to store various versions of that data for auditing purposes. The refined data could be on-chain, the raw price data could be on IPFS or equivalent, and any original URLs with prices of goods could potentially also be redundantly backed up using services like archive.is or web.archive.org. Data can be made available for periodic download (like MIT BPP) and hashed onto other chains (eg via Merkle trees), such that there are many different cryptographic integrity checks someone could run should they doubt any entry. Existing technologies like BitTorrent could be relied upon for dataset distribution and, as noted below, Chainlink's decentralized oracle networks could be used to cryptographically sign and deliver data on chain.
A multivariate time series of raw prices. If the data is parsed into relational format, a UPC (or more likely an internal version thereof) could be used to join price data across different sources. This would give a global dashboard for the price of everything; you could compare the price of a tea in a store in China to the price of the exact same tea in a different locale, or at a different time, to start visualizing the trajectory of prices over time. And you'd ideally have clickable attribution to the original archived data source for every price data point, retail and wholesale alike.
A smart contract to calculate inflation. We also want transparent logic, open source and ideally on-chain in a smart contract, to turn the price data from the decentralized datastore into various kinds of inflation estimates.
A way to do personalized inflation calculations. The ultimate version of the smart contract would allow you to pick some weighted basket of goods to get a personal inflation calculator. Is it your imagination, or have your personal costs for gas, food, rent, education, and healthcare been rising?
A calculation that doesn't rely on government statistics. This might go without saying, but all of this should be a bottom-up inflation calculation, using only the raw prices that people are paying on the web and in mobile apps as input. Government Consumer Price Index (CPI) data is useful only as a comparison, and shouldn't be an input to any calculation.
A security-conscious development process. There is good reason to do the project under a pseudonym, as it may help should the dashboard eventually be targeted for censorship. However, in order to award the prize and do the investment, we may need to know your identity for KYC purposes. We recognize this is a contradiction but will do our best to work with the winners to maintain their privacy while complying with all applicable laws. Note that you may also choose to use your real name, but simply decentralize the dashboard enough that it's out of your control.
How You Might Build An Inflation Dashboard, in Detail
The above was a quick summary of what we'd like to see. But there are several hard parts of building an open-source, censorship-resistant, on-chain inflation dashboard. Perhaps the toughest part involves actually acquiring the price data in the first place. With new tools, publishing it on-chain and calculating personalized, verifiable inflation estimates isn't that hard.
So let's go through the price part in some detail.
Acquiring Price Data
In order to calculate anything related to inflation, you need to collect data on prices for many goods over time. There are at least two ways to do this:
Option A: Scraping websites
Option B: Partnering with retailers (like Amazon and Alibaba) or with crypto merchant service providers (like BitPay and Coinbase Commerce)
Of these, the second may turn out to be the most feasible. To understand this, let's discuss why scraping isn't as easy as it may seem.
Option A: Acquiring Price Data by Scraping
The obvious way to build an inflation dashboard is to write code that collects prices over time for many different goods from many different websites and mobile apps. The naive approach would rely on the concept of a Universal Product Code (UPC) to make prices of different goods intercomparable across vendors and time periods. You'd obtain prices from both retail websites like Amazon (with products sold to end users) and wholesale websites like Alibaba (with bulk prices for enterprise buyers). And for the purposes of something like this project, you'd make all the code open source.
Why The Scraping Approach Has Issues
When you’re trying to scrape prices for any reason at all, you’re stepping into an arms race between retailers and price scrapers. The retailers are aware of the scrapers, and are always trying to either game them or block them outright.
The core dynamic that drives the entire scrapers vs. retailers arms race is this: retailers want to get users on-site by any means necessary, whereas scrapers are often building search engines.
While search engines want to only send a user to the “best” retailer for a particular query, retailers are strongly incentivized to stand out from the pack and get people onto their site at any cost. Once you’re on-site, even if what you came for is out of stock, they can try to sell you an upgrade, an accessory, or an alternative to the thing you were looking for.
This has many implications that will apply even to an inflation feed scraper that is using price data for a different purpose.
Issue: extracting data from a page
First, because retailers are always trying to play games with price scrapers, even getting data off a page and parsing it is nontrivial. You can’t rely on OpenGraph tags or site markup to provide structured data.
This can mean maintaining many site-specific scrapers using XPATH selectors and Regex. Retailers will change their markup a lot to tweak these pages so that all your XPATH queries break, and they do this just to frustrate scrapers. There are technologies that can work around this, like wrapper induction and newer machine-learning-based techniques.
Issue: dealing with automated countermeasures
Next, there are the mechanics of actually acquiring the raw HTML from merchant pages in the first place. Not only is it not trivial to parse a page, it's not always trivial to get the page content in the first place. Merchant pages' robots.txt files often ban any crawler not named GoogleBot, services like Cloudflare offer tools like Scrape Shield, and larger sites like Amazon and Alibaba have many custom defenses against scrapers.
Issue: maintaining the web crawler
Running web crawlers to do scraping can be an expensive fixed cost. It puts you directly in the middle of the arms race between search engines and retailers, where you’re constantly trying to battle the retailers for accuracy. They’re not going to know you’re an inflation feed — they’ll think your scraper is a comparison shopping scraper and block it.
Issue: detecting fake in-stock status
In order to get users on-site, retailers will do anything and everything to make it look like their item is in-stock when you view it from Google or some external engine. The idea is that even if the item you clicked through for is actually out-of-stock, once they have you on-site then you can be marketed to in other ways. Here's an example search result:

They claim the axe above is in-stock, but when you click through to the site you see this:

As you can see, you can’t select a variant to add to cart, which means it’s not actually available. This is just one random retailer, but tricks like this abound online.
What this stock status manipulation means for an inflation price scraper is that even an item that is not widely available may show as in-stock at a certain (bogus) price, where the apparent stock status and price are manipulated for the sole purpose of sucking in users from search and comparison shopping engines. If you’re trying to be accurate by only scraping real-world, market prices from in-stock listings, this presents an issue.
Issue: parsing hard-to-determine units
Another big problem for an inflation feed scraper is quantity-based pricing. If you’re trying to price, say, a fillet of salmon, you need to know if the price listed is per-pound or per-ounce. This is particularly important for an inflation feed. But as with price data itself, this data is hard to get, inconsistent across sites, and often requires XPATH queries. Take a look at this salmon listing and the markup


There’s a useful itemprop attribute there that gives you the list price and a sale price, but no itemprop that gives you the unit quantity. If you want that, you’ll need to XPATH and then REGEX.
Issue: catching hidden shipping prices
Shipping is another big area where online retailers play games to lure users in. You’ll see a ton of apparent variance in pricing that’s strictly a function of shipping estimates. Many retailers will advertise a low headline price, then pad the shipping considerably to make up the difference. Here’s a recent example from the front page of Google Shopping

You can see that the first site is playing around with delivery to get its listing to the top when sorted by price. Clicking through furthermore shows that shipping actually varies, and they’ve listed the low end of $15.99 for Google:

Again, this is all gamesmanship done in order to appear attractive to Google and to get the user on-site.
Issue: disambiguating UPCs and SKUs
You may want to compare scraped prices across sites, but UPC data in general is very sparsely available online. If you’re lucky you’ll get a SKU or some other code, but it’s often not clear if it’s manufacturer-provided or if it’s an internal code for the retailer itself. UPCs and other cross-site standardized numbers are very rarely available, or if they are present they are not reliable.
Additionally, different variants on a product will have different UPCs and SKUs and other numbers. For example, an office chair available in multiple colors will have a suite of different codes for each color. It’s hard for a scraper to figure out that these products are merely color or size variants on the same product.
You might still decide to write a scraper. But you should be aware of these issues before beginning.
Option B: Acquiring Price Data by Partnering
The alternative to scraping is partnering. As noted above, there are at least two ways to do this:
Partnering with large retailers like Amazon/Alibaba, or smaller online merchants.
Partnering with crypto merchant service providers, like Bitpay and Coinbase Commerce.
The first of these approaches is tough. Larger merchants generally have no incentive to work with you, and smaller merchants may not have the breadth of selection required to calculate a proper inflation feed


The second approach is more interesting, and it's a novel application of crypto commerce. Over the last several years, the business of accepting cryptocurrencies for online payments has grown quietly but substantially. Between Bitpay and Coinbase Commerce, 10000+ merchants have conducted $3B+ in cumulative sales.
A related set of companies are those which allow the use of cryptocurrency to back credit card purchases, like Coinbase (again), Gemini, Crypto.com, Wirex, and Blockfi. These may also have historical information on the price of goods in crypto terms.
The advantage of partnering with one of these companies to obtain a database of prices quoted in crypto terms is that (a) they are more likely to understand the problem Bitcoin solves, and (b) each has a single consistent historical database of prices across a wide variety of merchants that can be used (with some effort) to build up a historical inflation feed. The disadvantage is that the types of goods historically purchasable with crypto will be skewed relative to a traditional market basket; heavy on electronics and technology, light on consumer staples.
With that said, it may be worth combining the two approaches: some price data from scraping, and some from partnering. You might even be able to create some kind of crypto mechanism for a retailer to voluntarily (and perhaps pseudonymously) submit legitimate, representative price data without risking a loss of competitive advantage.
Publishing price data on-chain and calculating aggregates
Once you've got the price data, you want to get it on-chain to make it censorship-resistant. Perhaps not all of it goes on-chain – that can be expensive – but enough of it should be on-chain for skeptical users to verify as much as possible.
Chainlink is a widely used oracle that powers most of decentralized finance, which we think would be a good tool for this index, and combines tools for (a) multiple independent publishers of price data, (b) computational aggregation of that data, (c) a simple data.eth namespace to determine the data source and (d) bidirectional communication back and forth with off-chain resources (as of Chainlink 2.0). In particular, they have tutorials for:
launching Chainlink nodes to write data on-chain, including price data
calculating aggregates from on-chain and off-chain data (such as inflation estimates)
creating external adapters to make API calls
fetching commodity prices from smart contracts
Chainlink's developer documentation and support should be helpful here.
📋 Task: Earn a $100k investment and a $100K grant in LINK
Submit your censorship-resistant inflation dashboard.
A successful inflation dashboard could become the next coinmarketcap.com or defipulse.com – a seemingly simple but globally useful application.
We've outlined much of what we want to see above. We'll make a seed investment of $100k in the best entrant if you end up starting a company, with possible follow-on investment from @Sergeynazarov, @APompliano, @RussellOkung, and @RajGokal. And if you use Chainlink's oracle tech in your project, the best dashboard will be eligible to receive a $100k grant in LINK tokens. Please note that terms and conditions do apply, and any potential funding or grant may not be available in certain jurisdictions.
We're accepting submissions for the next 90 days. Once you're ready, just submit your project below for evaluation.